Macrocycles in the Protein Data Bank
The Protein Data Bank is an absolutely invaluable resource, the PDB is an archive of 3D structural information of proteins, nucleic acids, and bimolecular complex assemblies. However it is much, much more than a simple archive, the submitted structures are curated and annotated to add information about protein ID, sequence information, organism, ligand details etc. This allows users to interrogate the database in many different ways. The database currently holds 141209 entries, with over 10,000 new entries added every year. The vast majority are X-ray crystal structures but there are now over 12,000 NMR derived structures.
The PDB also contains 25626 chemical components - 24007 as free ligands in 106374 PDB file and you can search via a web interface or download the structures in sdf file format. However browsing through the downloaded file it was apparently that macrocycles were not well represented. A discussion with the extraordinarily helpful Rachel Kramer Green at PDB revealed the issue. Basically any ligand containing more that two amino-acids is treated as a protein not a ligand, there are other rules to deal with modified amino-acids etc. but the bottom line is that the only way to get a comprehensive view of macrocycles in the PDB is to download the entire PDB and programmatically by parsing the entire data set. Whilst a number of tools are provided to download individual or a selection of PDB files these are not really suitable for downloading the entire database. I decided to use the ftp download (you can set up an automated download/update using rsync). The download of the entire archive took several days but fortunately only has to be done once.
With the entire PDB archive available the next task is to parse it to identify macrocycles, first we need to decide what size ring constitutes a macrocycle. asking the "internet" failed to produce a definitive answer.
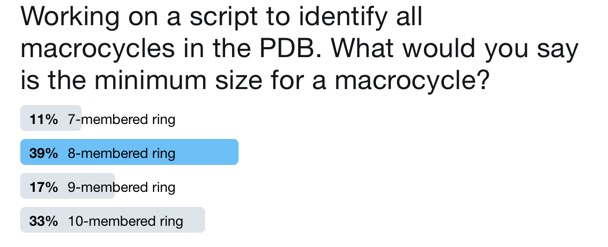
Whilst a 10-membered ring is certainly a macrocycle this would miss tripeptides, 7-membered rings like azepines certainly would not normally be classed as macrocycles so 8-membered ring seems to be the consensus. One advantage of querying a local dataset is that we can define what is a "macrocycle".
The next step was to parse the data to identify macrocycles, and Chris Williams at CCG was an enormous help in developing a script to search the downloaded PDB. The script can be downloaded here http://cambridgemedchemconsulting.com/resources/hitidentification/macrocycles/pdbextract_macrocycles.svl.zip.
Some of the script design considerations
The macrocycles are detected based on rules intended to capture reasonable macrocycles, and not small rings and/or large cross-linked protein cycles.
- max_mw: // macrocycle need a heavy-atom MW < max_mw
- max_ringsize: // moleucles with >max_ringsize atoms in the largest connected ring-block are too big
- min_ringsize: // molecules with
- min_nonfused: // minimum number of ring-block atoms NOT at ring fusion points
Whilst the original script had a user interface it soon became apparent that navigating to and selecting a folder containing over 200,000 items caused problems whilst the interface compiled and displayed the list of 200,000 items. So the command line interface turned out to be much more practical. After several iterations the script was refined to avoid a number of issues including splitting the system into separate molecules, which was consuming lots of memory with large systems.
The script is first loaded in MOE and the command issued via the SVL command line.
pdb_extract_macrocycles [max_mw:5000,min_ringsize:7,max_ringsize:50,pdb_dir:'/Volumes/StructuralDatabases/PDB/AllPDB/data/biounit/coordinates/all']
I ran it several times to search using the option for 7, 8, 9 and 10-membered maximum ring sizes. To see how the results compared with those ligands annotated in the PDB, a subset of macrocycles were exported in sdf format and imported into Vortex and the InChiKey generated, this was then used to search for PDB ligands. This met with limited success and it was clear that there were differences in the protonation state and it was necessary to use the "wash" command in MOE to clean up the extracted macrocycles. All entries were then exported in sdf format and imported into Vortex, the InChiKeys were then generated and the number of unique macrocycles determined. Duplicate entries can occur for several reasons, there may be multiple PDB entries for a single protein or the same macrocycle may be a ligand for multiple different proteins. The majority of the duplicates are entries that contain a porphyrin ring.
The SVL script can be dowloaded from here [Need to insert link], this script requires access to MOE.
| Minimum size of macrocycle | Number of PDB entries containing a macrocycle | Number of unique macrocycles | ||
| 10 | 6894 | 2587 | ||
| 9 | 6957 | 2611 | ||
| 8 | 7288 | 2698 | ||
| 7 | 8755 | 3284 | ||
As expected setting the minimum ring size to 10 identified the smallest number of macrocycles, increasing the ring size to 9 identified an additional 24 macrocycles. Some of the additional structures are shown below, the cyclic phosphate is a bit of a concern since it appears to contain a trivalent oxygen!
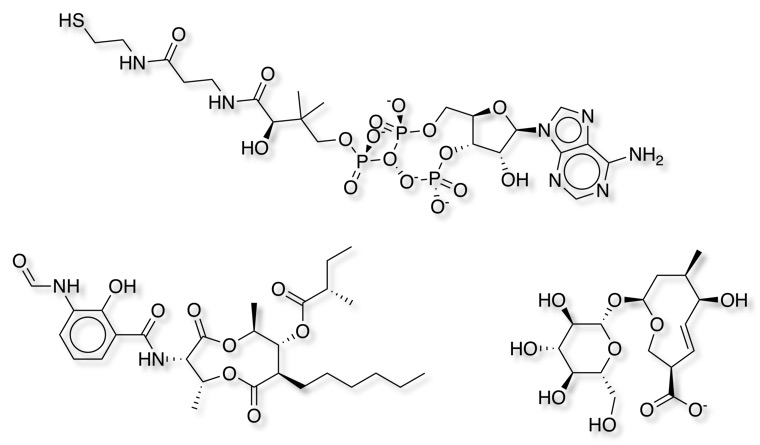
Reducing the ring size further identified more entries but to be honest I would not regard them as "Macrocycles" since it included benzodiazepines etc.
Using the 9-membered ring as the cut-off the structures were imported into Vortex, the InChiKey was generated and a script was used to search UniChem using the InChiKey to search for the existence of the molecule in multiple databases (including PDB).
UniChem allows users to create links between structures and identifiers in different sources on the basis of complete identity between InChIKeys
Of the 2611 unique macrocycles identified 2475 were not in the PDB ligand database and 2338 did not have PubChem identifiers. The molecular weight range was 208 to 5384 however, whilst the rule of 5 (Ro5) has provided a useful way to describe small molecule drug space it is also clear that there are a significant number of molecular classes that exist beyond the rule of 5 boundaries (bRo5). In a review of the AbbVie compound collection DOI they were able to identify key findings that might explain the success (or failure) of bRo5 projects. From an analysis of a variety of calculated physicochemical properties they proposed a simple multiparametric scoring function (AB-MPS) was devised that correlated preclinical PK results with cLogD, number of rotatable bonds, and number of aromatic rings.
AB-MPS = Abs(cLogD-3) + NAR + NRB
Where cLogD was the calculated LogD (ChemAxon), NAR is number of aromatic rings, NRB is number of rotatable bonds (pipeline pilot calculations), with AB-MPS values of ≤14 predicting a higher probability of success. Compounds with AB-MPS <14 on average had better bioavailability and PAMPA cell penetration. I used a Vortex script to calculate ABmps for all 2611 entries and the results are displayed below. The coloured points are those identified in PubChem.

Clearly there are a large number of macrocycles with little data associated with them.
I'm continuing to work with CCG to refine the script and will update this page with new observations.
Last Updated 25 June 2018